
얀 르쿤 메타 최고 AI 과학자 [사진=메타 AI 웹사이트]
페이스북·인스타그램 운영사 메타(Meta)가 생성 인공지능(AI) 분야 기술 경쟁에서 주도권을 확보하기 위해 새로 설계한 AI 모델과 방법론을 공개했다. ‘이미지 공동 임베딩 예측 아키텍처(I-JEPA)’라는 이름이 붙은 메타의 새 AI 모델은 여타 생성 AI 모델보다 효율적으로 이미지 데이터를 학습하고 빠르게 결과물을 만들어낸다.
메타의 새 모델은 주어진 정보를 이용해 결과물을 만드는 ‘예측’ 작업을 수행할 때 사람처럼 외부 세계에 대한 배경 지식을 이용한다. 기존 AI는 인체에 대한 지식이 없어 이미지로 생성한 인물의 손가락 수를 정확하지 않게 표현하거나 다리를 모두 왼쪽으로 묘사하는 등 오류를 보이는데, I-JEPA가 이런 문제를 없앨 수 있게 된다.
22일 메타에 따르면 세계 AI 분야 4대 석학 중 한 명인 얀 르쿤(Yann LeCun) 메타 최고 AI 과학자의 이론이 I-JEPA 모델의 설계 방법론 핵심을 이루고 있다. 메타는 지난주 이 모델 훈련 코드와 체크포인트를 오픈소스로 공개하고 이번주 캐나다 밴쿠버에서 열린 국제 학회 ‘CVPR 2023’에서 연구 논문을 발표했다.
I-JEPA 모델을 개발한 메타 연구원들은 인간이 외부 세계를 관찰하기만 해도 ‘상식(common-sense)’이라고 불리는 방대한 배경 지식을 배운다는 점에 주목했다. 이들은 메타의 새로운 AI가 상식적 배경 지식을 포착하고 이후 컴퓨터가 다루기에 알맞은 데이터로 바꾸는 학습 알고리즘을 고안하고자 했다.
연구원들은 AI가 습득할 상식적 배경 지식을 효율적으로 제공하기 위해 이미지·음향 등 학습용 데이터를 활용하는 방법으로 AI 모델이 스스로 주어진 데이터를 분류해 나가는 자기지도학습(Self-supervised learning)을 선택했다. 사진과 소리를 일일이 분류한 데이터세트를 쓰지 않고 분류가 안 된 데이터를 직접 학습하게 했다.
이렇게 개발된 모델인 I-JEPA의 원천 설계 구조인 ‘공동 임베딩 예측 아키텍처(JEPA)’는 입력된 이미지나 텍스트의 일부 표현을 예측하기 위해 주어진 데이터의 나머지 정보를 활용한다. 실제 예측을 수행할 때 이미지를 형성하는 화소 값 등 세부 사항을 일일이 예측하는 대신 추상적인 표현을 예측하는 방법을 취했다.
생성 AI 모델이 세부 사항을 일일이 예측하려고 하면 결과물에 오류가 많아진다. 여타 생성 AI 모델을 이용하는 현존 서비스 대부분이 이런 문제를 보여 주고 있다. 예를 들어 생성된 이미지 속 인물의 손이나 발 모양을 제대로 생성하지 못하는 것이 대다수 이미지 생성 AI 모델의 문제점으로 남아 있다.
메타 연구원들은 이에 대해 “세상이 본질적으로 예측할 수 없음에도 모델이 누락된 정보의 모든 부분을 채우려 한다”며 “결과적으로 예측 가능한 추상적 개념을 포착하는 대신 관련 없는 세부 사항이 너무 많이 집중해 사람이 절대 하지 않을 실수를 저지르기 쉽다”고 지적했다.
I-JEPA는 누락된 정보를 예측할 때 추상적 표현을 예측하도록 설계됐다. 연구원들은 “화소 단위의 세부 정보를 제거하는 추상적인 예측 타깃을 이용해 AI 모델이 ‘의미론적 특징(semantic features)’을 더 많이 학습하도록 유도한다”며 “공간적으로 분산된 정보의 맥락을 이용해 더 큰 규모의 의미론적 정보를 예측”한다고 설명했다.

I-JEPA 모델이 불완전한 개 얼굴 이미지에서 각 부분 옆 지워진 영역에 들어갈 요소를 예측(추론)해 채워넣는 과정을 나타낸 도안 [사진=메타 AI 웹사이트]
메타는 이런 특성을 갖춘 I-JEPA가 생성한 이미지 결과물 품질이 더 뛰어나다고 강조했다. 한쪽 귀와 눈, 꼬리를 포함한 몸뚱이가 지워진 개의 정면 얼굴 사진을 입력하면 I-JEPA는 지워지지 않은 머리, 코와 입, 목 부분을 각각 인식하고 그에 인접한 예측 타깃 영역에 각각 알맞은 표현을 만들어낼 수 있음을 예로 들었다.
I-JEPA는 모델 개발에 드는 시스템 자원 비용이나 사전훈련(pretraining) 속도도 기존 모델보다 효율적이다. 예측 작업 계산을 위해 여러 개의 뷰(view)를 만들지만 이에 따른 과부하는 발생하지 않고, 수작업 데이터 증강에 의존한 기존 의미론적 사전훈련 방식보다 사물 갯수 세기나 깊이 예측 등 작업 성능이 더 높다는 것이다.
연구원들은 JEPA 개발 방법론을 이용해 6억3200만개 파라미터를 다루는 AI 모델 훈련에 엔비디아 그래픽처리장치(GPU) ‘A100’을 16개 사용해 72시간만에 끝냈다고 강조했다. 이에 대해 다른 개발 방법론을 이용할 때 동일한 GPU를 사용하면 통상 2배에서 10배 시간이 걸려, 그만큼 메타의 방식이 탁월하다고 주장한 것이다.
또 “I-JEPA는 수작업 이미지 변환으로 인코딩한 추가 지식 없이 경쟁력있는 기성 이미지 표현을 학습하는 아키텍처의 잠재력을 보여준다”며 “일반적인 세계 모형을 학습해 JEPA를 고도화하면 영상 속 미래 사건에 대한 광범위한 시공간 예측을 수행하고 오디오·텍스트 프롬프트로 조건을 붙일 수 있게 된다”고 했다.
메타는 자신들이 연구한 생성 AI 기술 JEPA로 텍스트뿐 아니라 이미지와 음향이 포함된 영상까지 만들어낼 수 있게 할 계획이다. 이 모델이 이미지와 텍스트를 짝지은 데이터 쌍이나 영상 데이터 등을 자기지도학습 방법으로 학습하게 함으로써 세계 모형, 즉 상식적인 배경 지식을 얻게 한다는 구상이다.
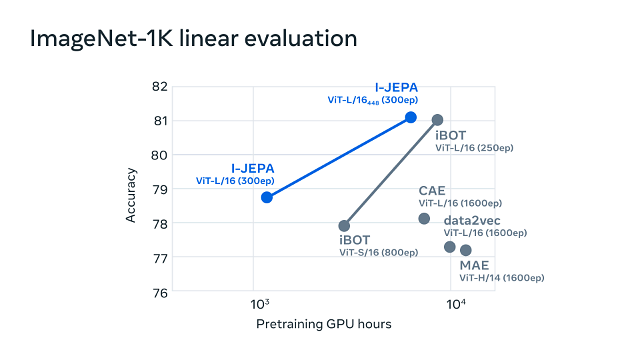
I-JEPA 모델의 사전훈련 연산 단위시간(GPU hour)당 이미지넷 데이터 예측 성능(추론 정확도)이 선형적으로 개선되는 양상을 나타낸 도안 [사진=메타 AI 웹사이트]

임민철 기자imc@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



