음성에 담긴 감정을 분석해 영상 속 인물의 표정을 자연스럽게 바꾸는 인공지능(AI) 기술이 국내 연구진에 의해 개발됐다고 연합뉴스가 18일 보도했다.
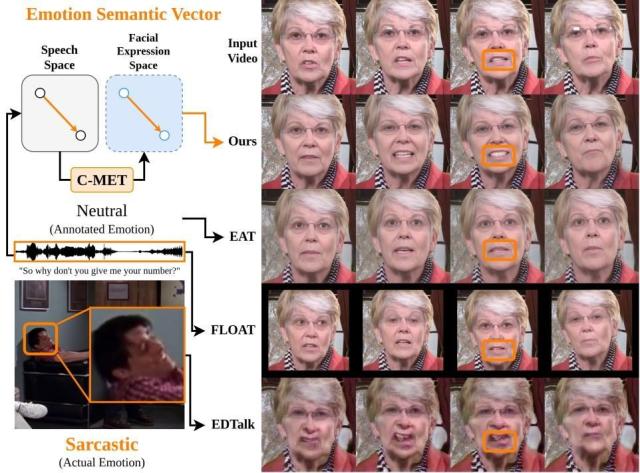
연합뉴스에 따르면 울산과학기술원(UNIST) 인공지능대학원 김태환 교수 연구팀은 음성 신호에서 감정을 추출해 별도의 참조 이미지 없이도 영상 속 화자의 표정을 원하는 감정으로 변경할 수 있는 AI 모듈 'C-MET(Cross-Modal Emotion Transfer)'를 개발했다.
이번 기술은 단순히 '기쁨'이나 '슬픔'처럼 감정에 이름표를 붙여 학습하는 기존 방식과 달리, 감정 사이의 변화량에 주목한다는 점이 특징이다. 연구진은 중립적인 음성과 감정이 실린 음성의 차이를 벡터 형태의 수치 정보로 계산한 뒤, 해당 변화가 얼굴에 어떤 표정 변화로 나타나는지 AI가 학습하도록 했다.
이를 통해 말의 내용과 감정이 섞여 있는 음성에서도 표정 변화에 필요한 감정 신호만 따로 추출할 수 있다. 같은 문장이라도 말투와 어조에 따라 입꼬리와 눈썹, 눈 주변 움직임이 달라지도록 표정을 변화시킬 수 있다는 설명이다.
특히 기존 학습 과정에서 직접 접하지 못한 감정도 표현할 수 있다는 점이 주목된다. 연구팀은 두 감정 사이의 변화량을 분석하는 방식을 활용해 비꼼, 공감, 카리스마 등 미묘한 감정까지 표정에 반영할 수 있다고 밝혔다.
예를 들어 "잘한다"라는 말도 진심 어린 칭찬인지, 비꼬는 의미인지를 어조만으로 구분해 서로 다른 표정으로 구현할 수 있다.
또한 감정을 표현한 정면 사진 등 고품질 참조 이미지가 필요하지 않아 활용 범위가 넓다는 장점도 있다.
성능 역시 기존 기술보다 향상됐다. 연구진이 최신 표정 편집 기술인 이디톡(EDTalk)의 표정 인코더를 C-MET로 대체해 실험한 결과 감정 표현 정확도는 41.99%에서 55.91%로 약 14%포인트 높아졌다.
또 다른 얼굴 생성 모델인 PD-FGC에 적용했을 때도 감정 정확도가 33.36%에서 36.82%로 개선됐다. 이는 C-MET가 특정 모델에 국한되지 않고 다양한 얼굴 생성 AI 시스템에 적용될 수 있음을 보여주는 결과라고 연구진은 설명했다.
김태환 교수는 연합뉴스를 통해 "이번 연구는 참조 이미지 없이 음성만으로 얼굴 영상의 감정을 바꿀 수 있다는 점에서 기존 방식의 한계를 실질적으로 해결했다"며 "가상 인간 제작과 영화·콘텐츠 후반 작업, 감정 인식 AI 등 다양한 분야에서 활용될 수 있는 기반 기술"이라고 말했다.
이번 연구 성과는 AI·컴퓨터 비전 분야 국제학회인 'CVPR 2026(Conference on Computer Vision and Pattern Recognition)'에 채택됐다.
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



