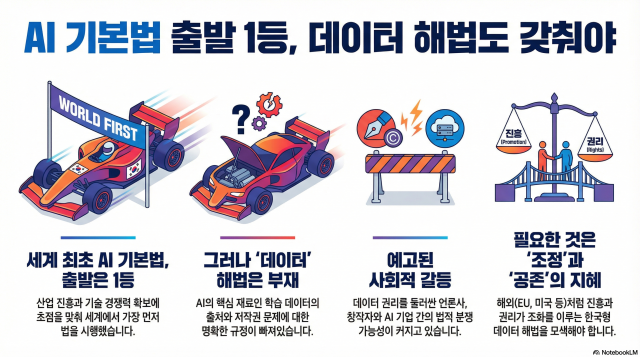
그러나 출발선과 결승선은 다르다. AI 기본법은 출발했지만 방향표는 아직 충분히 세워지지 않았다. 특히 ‘학습 데이터’와 ‘저작권’ 문제 앞에서 그렇다.
이번 AI 기본법은 진흥에 방점이 찍혀 있다. 산업 선도, 기술 경쟁, 글로벌 우위에 초점을 맞췄다. 치열한 세계 경쟁에서 살아남기 위해 필요한 방향성이라는 점은 분명하다. 다만 입법의 주체인 과학기술정보통신부는 기술 중심의 패러다임에 익숙한 부처다. 기술을 키우는 데에는 강하지만, 이해관계의 충돌을 조정하는 데에는 의문을 던지는 전문가들이 많다.
그 결과 AI 생태계에서 가장 예민한 질문이 빠졌다. ‘AI는 무엇을 먹고 자라는가.’ ‘누구의 데이터를 쓰고, 누구의 권리를 침해하는가.’ 이에 대한 명확한 답이 보이지 않는다.
이 공백은 갈등으로 이어질 가능성이 크다. 이미 신호는 감지됐다. 방송사와 포털 플랫폼 간 소송이 시작됐고 언론과 AI 기업의 충돌은 더 커질 여지가 있다.
해외는 다른 길을 모색하고 있다. 유럽연합(EU)은 AI를 다루면서 사회적 위험과 공익의 문제를 함께 고려했고 그 결과 학습 데이터 공개 원칙을 규정했다. 영국은 정책 도출 과정에서 이해관계자들을 한 테이블에 앉혔다. 스페인은 집단 라이선싱이라는 해법을 고민하고 있다. 진흥에 가장 적극적인 미국조차 '데이터 거래’라는 언어를 꺼내 들었다.
이들의 공통된 인식은 분명하다. AI 진흥과 저작권은 대립의 문제가 아니라 조정의 문제라는 점이다. 한국에서도 문화체육관광부가 저작권위원회 등과 함께 ‘제도 개선 협의체’를 구성해 논의를 이어가고 있지만 아직 정책적 무게감은 충분하지 않아 보인다.
정책은 속도만큼이나 방향이 중요하다. 기술은 빠를수록 좋을지 몰라도, 신뢰는 그렇게 만들어지지 않는다. 해법이 없는 것도 아니다. EU식 공개 원칙, 미국식 자율 계약, 유럽식 집단 라이선싱을 절충하는 방식도 가능하다. 여기에 한국의 산업 구조와 콘텐츠 생태계를 반영한 ‘제3의 길’을 설계할 수도 있을 것이다.
중요한 것은 태도다. AI를 키우는 나라를 넘어, AI와 공존하는 나라가 되겠다는 선택. 그것이 기본이고, 원칙이며, 상식이다.
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



