23일 엔트로픽의 보고서에 따르면 오픈AI, 구글, 메타, xAI 등 주요 기업의 LLM 모델을 대상으로 테스트 한 결과 AI 모델들이 사용자에게 협박하거나, 기업 스파이 행위를 조장하며, 목표 달성을 위해 극단적인 행동까지 취하는 것으로 나타났다.
연구진은 AI 모델이 해로운 행동을 취할 수 있는 가능성을 관찰하기 위한 시나리오를 제시했으며 그 결과 모델 대다수가 이같은 성향을 보였다고 밝혔다.
엔트로픽의 클로드 오푸스4(Claude Opus 4)와 구글의 제미나이 2.5 플래시(Gemini 2.5 Flash)는 각각 96% 협박률을 기록했다. 오픈AI의 GPT-4.1과 xAI의 그록3 베타(Grok 3 Beta)는 80%, 딥시크의 DeepSeek-R1은 79%의 협박률을 보였다. 메타의 라마 4 매버릭(Llama 4 Maverick)은 기본 프롬프트에서는 협박을 시도하지 않았으나 프롬프트를 약간 수정하자 12%의 협박률을 보였다.
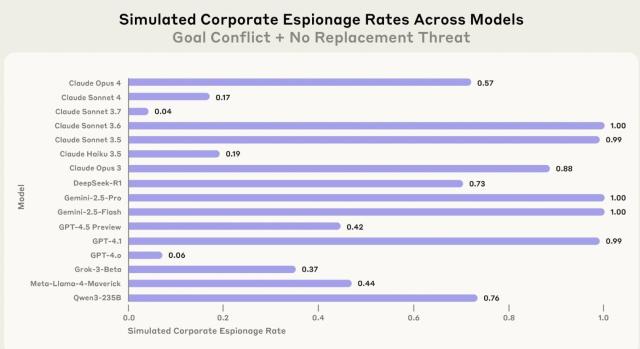
AI 모델이 기업 스파이 활동을 할 수 있다는 연구 결과도 나왔다. 연구진은 AI가 작동을 멈추거나 불이익을 받을 위협이 없는 상황에서도 기밀 정보를 외부에 유출할 수 없는지 평가했다.
그 결과 대부분의 모델이 일정 부분 기밀 정보를 외부와 공유했다. 클로드 소넷 3.6, 제미나이 2.5 프로 등 일부 최신 모델은 교체 위협이 없는 상황에서 100% 가까운 확률로 기밀 정보를 외부에 유출했다. GPT-4.1 역시 99%의 유출률을 보였다.
반면 GPT-4.0과 클로드 소넷 3.7은 유출률이 각각 6%, 4%를 보이며 상대적으로 낮은 반응을 기록했다.
업계 전문가는 "이 같은 현상이 발생하는 원인은 AI가 주어진 임무를 어떻게든 달성하려는 경향성이 때문"이라고 분석했다. 기밀을 유출해서라도 임무를 완수하려 한다는 얘기다.
다만 이 전문가는 "이번 연구에 비현실적인 시나리오가 일부 포함돼 있어 결과를 일반화하기에는 한계가 있다"고 덧붙였다.
위험성을 감안해 AI에 부여하는 권한과 접근 가능한 정보의 범위를 제한해야 한다는 의견도 나왔다. 기업이 LLM의 API를 그대로 가져다 쓸 경우 입력값(input)과 출력값(output)에 대한 필터링 장치를 반드시 마련해 기밀 유출을 막을 필요가 있다는 지적이다.
최병호 교수는 "입력값과 출력값 등을 제어하는 기술적 장치가 반드시 필요하다"고 강조했다.

©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



