21일 업계에 따르면, 네이버클라우드 하이퍼클로바X팀은 지난 18일 논문 사전공개 사이트 '아카이브(arXiv)'와 AI 오픈소스 커뮤니티 '허깅페이스'를 통해 'K-MMLU(Measuring Massive Multitask Language Understanding in Korean)'를 공개했다. 네이버클라우드는 오픈소스 언어모델(LM) 연구팀인 '해례(HAERAE)' 팀과 협업을 통해 이를 구축했다.
MMLU(대규모다중작업언어이해)는 AI 테스트의 일종이다. 수학·물리학·역사·법률·의학·윤리 등 57개의 주제를 복합적으로 활용해 AI의 지식과 문제 해결 능력을 평가하는 지표다. 오픈AI와 구글 등 LLM 선두 업체들도 MMLU 결과를 토대로 자사 모델의 우수성을 설명한다. 다만 기존 MMLU는 아무래도 영어에 기준이 맞춰져 있었다. 즉 K-MMLU를 통해 한국어 LLM의 성능을 객관적으로 짚어볼 수 있는 셈이다.
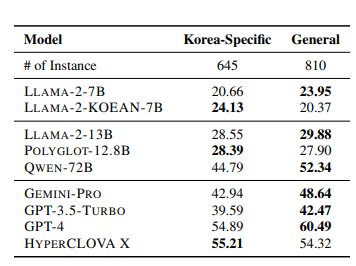
K-MMLU 개발팀은 아카이브에 게재된 논문 소개글에서 "기존 영어 벤치마크를 번역한 한국어 벤치마크와 달리, K-MMLU는 한국어 시험에서 데이터를 직접 수집해 한국어의 언어적·문화적 측면을 반영한다"고 설명했다. 이를 통해 한국어는 물론 한국에 특화된 다양한 지식들까지 평가할 수 있다. 향후 한국어 LLM이나 sLLM을 만드는 개발자들이 이를 통해 언어모델의 성능을 보다 정확하게 확인할 수 있게 될 전망이다.
한국 특화 지식이 아닌 일반적인 지식 측면에서는 GPT-4가 60.49점으로 하이퍼클로바X(54.32)를 앞섰다. 다만 여기서도 하이퍼클로바X는 제미나이 프로(48.64)와 GPT-3.5 터보(42.47)를 제치며 전반적인 한국어 처리 능력이 우수함을 입증했다.

윤선훈 기자chakrell@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



