
샘 앨트먼 오픈AI 최고경영자 [사진=AFP·연합뉴스]
14일(현지시간) 오픈AI는 차세대 언어모델인 GPT-4를 자사 홈페이지를 통해 공개하고 유료 구독 서비스인 '챗GPT 플러스'를 통해 사용할 수 있다고 밝혔다.
GPT-4는 GPT-3.5와 비교해 언어 생성 능력이 더욱 향상되고 이미지를 인식(컴퓨터 비전)할 수 있는 기능이 추가된 것이 특징이다.
이를 두고 오픈 AI는 "GPT-4는 다양한 시험과 학술 벤치마크에서 인간 수준의 성능을 보여주는 초거대 멀티 모달 AI(Large Multimodal Model)로, 미국 변호사 시험에서 하위 10%의 성적을 낸 GPT-3.5와 달리 상위 10% 점수를 받을 수 있을 정도로 언어 능력을 향상했다"고 밝혔다.
오픈AI는 과거 GPT3에서 GPT-3.5로 AI 모델을 업그레이드하는 데 2년이 넘는 시간이 필요했던 것과 달리 GPT-3.5에서 GPT-4로 모델을 강화하는 것에는 불과 반년밖에 걸리지 않았다. 이는 오픈AI에 대규모 투자를 하고 클라우드를 통해 대규모 AI 반도체 인프라(엔비디아 GPU팜)를 제공한 마이크로소프트와 긴밀한 협력이 있었기에 가능한 일이다.
오픈AI는 "회사는 지난 2년 동안 전체 딥러닝 스택을 재구축했으며 (초거대 AI 모델 실행을 위한) 작업 부하를 최소화하기 위해 마이크로소프트와 클라우드 기반 슈퍼컴퓨터를 공동 설계했다"며 "이를 통해 GPT-4 학습 과정은 전례 없이 안정적이었으며 AI 모델의 학습 성능을 사전에 정확하게 예측할 수 있는 최초의 대형 모델이 됐다"고 설명했다.
이용자는 챗GPT 플러스에 가입하면 GPT-4 기반 차세대 챗GPT를 사용할 수 있다. 다만 GPT-4 기반 챗GPT는 클라우드 서버 부하로 인해 현재 사용량이 4시간에 질문 100개로 제한되어 있고, 사용 한도가 꽉 차면 GPT-3.5 기반으로 사용해야 한다. 오픈AI는 지속해서 AI 모델을 최적화하고 AI 반도체를 확충함으로써 일일 사용량을 확대할 계획이라고 밝혔다.
챗GPT 무료 이용자는 GPT-4 기반 챗GPT를 사용할 수 없다. 기업과 개발자는 GPT-4 유료 API 사용 신청을 함으로써 GPT-4와 자사 서비스를 연결할 수 있다.
◆美 변호사 시험 상위 10%...약점인 수학 능력도 강화
오픈AI는 GPT-4의 언어 능력을 두고 "일상적인 대화에선 (GPT-3.5와) 큰 차이를 느낄 수 없지만 전문적인 질문을 하면 차이가 나타난다"며 "더 안정적이고 창의적이며 미묘한 질문에 대해 답변한다"고 밝혔다.
일례로 GPT-3.5는 미국 변호사 시험에서 400점 만점에 213점을 받았지만, GPT-4는 400점 만점에 298점을 받아 법률 지식을 한층 끌어올렸다. 미국 수학능력시험인 SAT의 경우 읽기 및 쓰기의 경우 800점 만점 기준 670점에서 710점으로 향상됐고, 특히 GPT-3.5의 약점으로 지적받은 수학 능력의 경우 590점에서 700점으로 크게 향상됐다. 의학지식 자가 진단도 정답률이 53%에서 75%로 향상됐다.
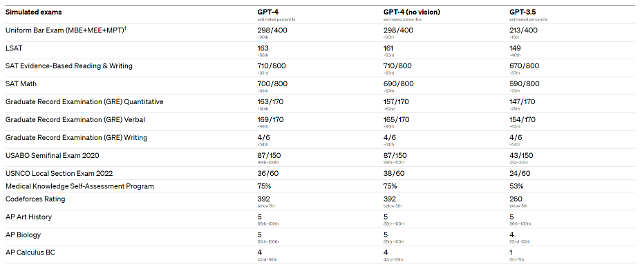
각종 시험에서 챗GPT-4와 챗GPT-3.5 정답률 비교 [사진=오픈AI]
또 오픈AI는 다방면으로 활용할 수 있는 트랜스포머 모델의 특징을 살려 GPT-4에 자연어 처리뿐 아니라 이미지를 이해할 수 있는 능력(컴퓨터 비전)도 추가했다. 이용자가 업로드한 이미지를 보고 이에 맞는 최적의 답변을 한다. 다만 이미지 이해하기는 시험 기능으로 이용자에게 바로 제공하지는 않는다.
오픈AI는 GPT-4가 GPT-3.5의 단점으로 지적받은 '환각 오류'를 완전히 해결하지는 못했다고 강조했다. 환각 오류란 AI가 사실(팩트)과 다른 것을 마치 진실인 것처럼 강한 확신을 담아 답변하는 문제를 말한다. 때문에 GPT-4를 통해 얻은 답변이라도 실제 업무나 논문 등에 활용하려면 강력한 팩트 체크 과정을 거쳐야 한다. 다만 GPT-4는 오픈AI가 실시한 적대적 사실성 평가에서 GPT-3.5보다 40% 높은 점수를 받아 환각 오류를 상당 부분 줄이는 데 성공했다.
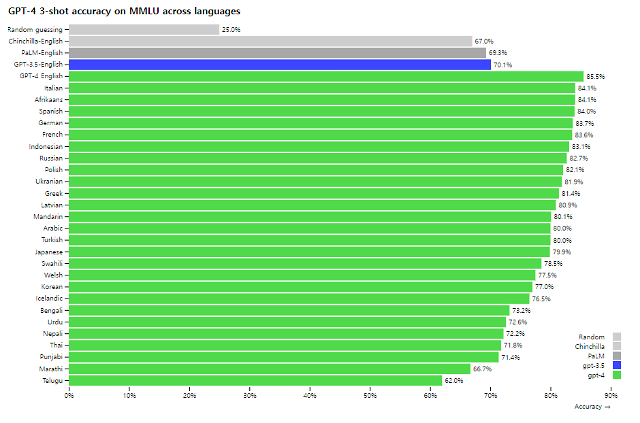
GPT-4.0 전 세계 언어 대답 능력 벤치마크 결과 [사진=오픈AI]
다만 2021년 9월 이전 정보만 정확히 답변하고 그 이후 정보는 제한적으로만 답변하는 문제는 그대로다. 답변 데이터를 최신화하는 일정은 아직 공개하지 않았다.
샘 앨트먼 오픈AI CEO는 트위터를 통해 "GPT-4는 여전히 결함이 있고 제한적이다. 하지만 더 많이 사용해보니 처음 사용할 때보다 더 인상적이다"라고 밝혔다.
한편 오픈AI는 듀오링고, 비마이아이즈, 스트라이프, 모건스탠리 등 미국 기업과 스타트업이 GPT-4를 자사 업무와 서비스에 도입하기로 했다고 밝히며 초거대 AI 수익화에도 속도를 내고 있음을 강조했다.
[사진=트위터 갈무리]

강일용 기자zero@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



